义相似度
语义相似度是通过 embedding 模型得到 answer 和 ground_truth 的文本向量,然后计算两个文本向量的相似度。向量相似度的计算有许多种方法,如余弦相似度、欧氏距离、曼哈顿距离等, Ragas 使用了最常用的余弦相似度。
在评估 RAG 应用整体回答质量时,使用 Ragas 的 Answer Correctness 是一个很好的指标。为了计算这个指标,你需要准备以下两种数据来评测 RAG 应用产生的 answer 质量:
- question(输入给 RAG 应用的问题)
- ground_truth(你预先知道的正确的答案)
3. 熟悉 RAG 的工作流程
截至目前,你已经完成了一些改进,让答疑机器人的问答准确度更高了。但在实际生产环境中,你可能会遇到的问题远不止于此。之前你已经了解了一些 RAG 的工作流程,在这里你可以回顾一下重要的步骤,方便你发现新的改进点:
RAG(Retrieval Augmented Generation,检索增强生成)是一种结合了信息检索和生成式模型的技术,能够在生成答案时利用外部知识库中的相关信息。它的工作流程可以分为几个关键步骤:解析与切片、向量存储、检索召回、生成答案等。具体的概念你可以回顾"扩展答疑机器人的知识范围"这一节。
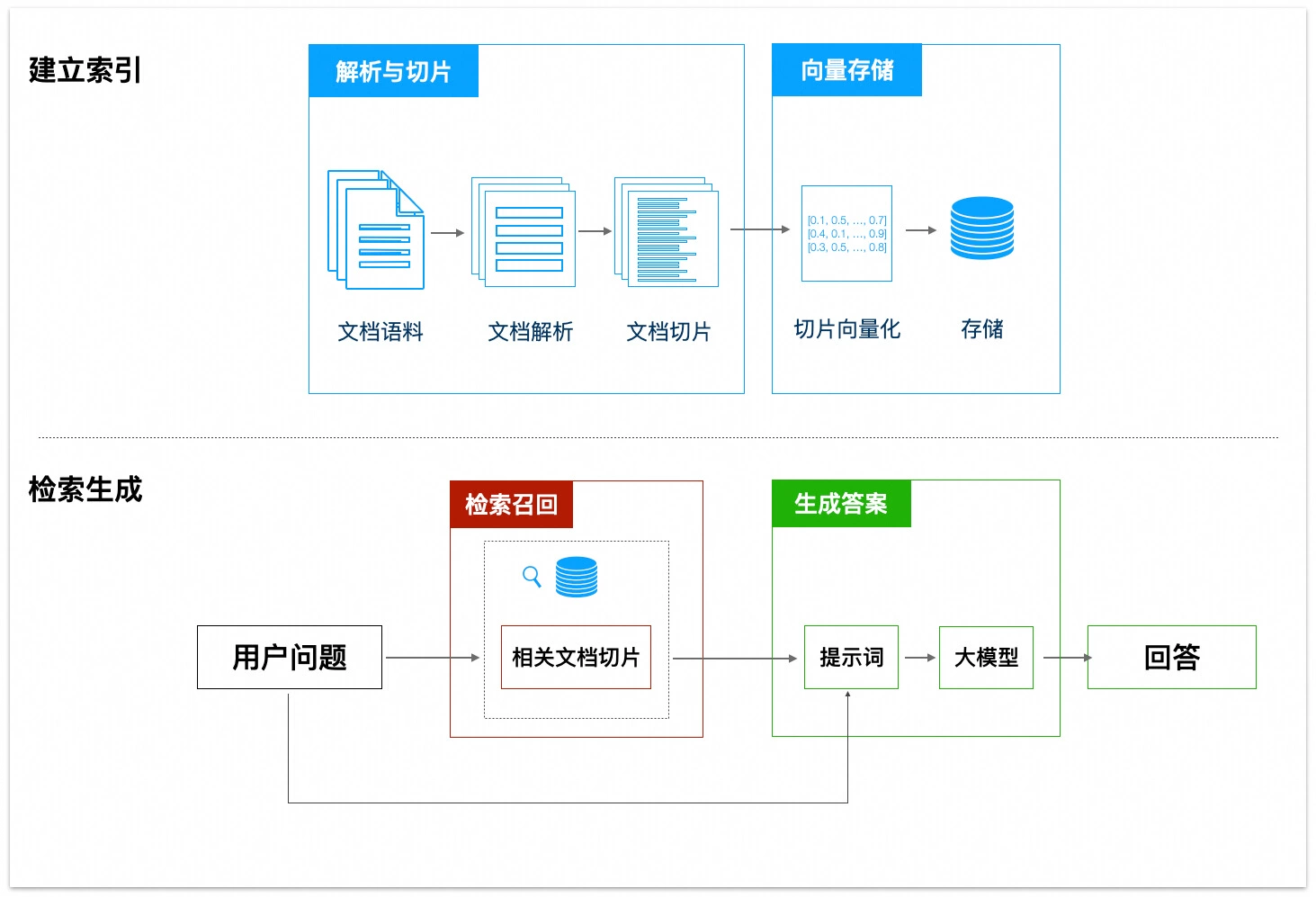
-
文档准备阶段,比如客服系统
- 意图空间
- 知识空间
重叠区域:rag应用效果保障基础,对于用户意图,通过优化内容质量,优化工程和算法,不断提升回答质量
未被覆盖的意图空间: 缺乏知识库内容职称,容易输出幻觉的回答,需要补充缺漏的知识
未被利用的知识空间:召回不相关知识点可能会干扰大模型回答,优化召回算法避免召回无关内容以及定期查验知识库,剔除无关内容
注: 尝试优化工程或者算法前,应该构建一套可持续收集用户意图的机制,通过采集真实用户需求来完善知识库, 并邀请用户意图有深刻理解的领域专家参与效果评估,形成“数据采集-知识更新-专家验证”的闭环优化流程,保证RAG应用的效果。
-
文档解析与切片阶段
- 切片信息完整,不能过多或过少,不要有太多干扰信息。
文档解析问题
- 文档类型不统一,开发对应的解析器,或者转文档格式
- 已解析的文档格式嵌入表格图片视频,改进解析器
文档切片问题
1、 文档有很多主题接近的内容,比如工作手册文档中,需求分析、开发、发布等每个阶段都有注意事项、操作知道
通过扩写文档标题以及子标题【注意事项】=>文档a-项目a-注意注意事项这种,通过扩展标题和打标
2、文档切片过长,引入干扰项,结合业务,减少切片长度,确保每个切片只包一个主题
3、文档切片过短, 有效信息呗阶段,检索时候无法获取完整的上下文信息
切片方法
1、Token切片:适合对Token数量有严格要求,比如使用上下文长度较小的模型时候。
示例文本: "LlamaIndex是一个强大的RAG框架。它提供了多种文档处理方式。用户可以根据需要选择合适的方法。"
使用Token切片(chunk_size=10)后可能的结果:
- 切片1: "LlamaIndex是一个强大的RAG"
- 切片2: "框架。它提供了多种文"
- 切片3: "档处理方式。用户可以"
2、句子窗口切片:每个切片都包含周围的句子 作为上下文窗口
每个切片都包含周围的句子作为上下文窗口。
示例文本使用句子窗口切片(window_size=1)后:
- 切片1: "LlamaIndex是一个强大的RAG框架。" 上下文: "它提供了多种文档处理方式。"
- 切片2: "它提供了多种文档处理方式。" 上下文: "LlamaIndex是一个强大的RAG框架。用户可以根据需求选择合适的方法。"
- 切片3: "用户可以根据需求选择合适的方法。" 上下文: "它提供了多种文档处理方式。"
3、语义切片
示例文本: "LlamaIndex是一个强大的RAG框架。它提供了多种文档处理方式。用户可以根据需求选择合适的方法。此外,它还支持向量检索。这种检索方式非常高效。"
语义切片可能的结果:
- 切片1: "LlamaIndex是一个强大的RAG框架。它提供了多种文档处理方式。用户可以根据需求选择合适的方法。"
- 切片2: "此外,它还支持向量检索。这种检索方式非常高效。" (注意这里是按语义相关性分组的)
4、markdown切片
专门针对 Markdown 文档优化的切片方法。
示例 Markdown 文本:
# RAG框架
LlamaIndex是一个强大的RAG框架。
## 特点
- 提供多种文档处理方式
- 支持向量检索
- 使用简单方便
### 详细说明
用户可以根据需求选择合适的方法。
Markdown切片会根据标题层级进行智能分割:
- 切片1: "# RAG框架\nLlamaIndex是一个强大的RAG框架。"
- 切片2: "## 特点\n- 提供多种文档处理方式\n- 支持向量检索\n- 使用简单方便"
- 切片3: "### 详细说明\n用户可以根据需求选择合适的方法。"
选择切片方法总结:
1. 刚开始接触,优先使用默认的句子切片,大多数场景适用
2. 当检索效果不够理想可以尝试:
1. 处理长文档且需要保持上下文,试试句子窗口切片
2. 文档逻辑性强、内容专业?语义切片可能有帮助
3. 模型总报Token超限,Token切片精确控制
4. 处理markdown文档?有专业的markdown切片
没有最好的切片方法,只有适合的场景,尝试不同的切片方法,观察Ragas评估效果,找到最适合需求的方案。
切片向量化与存储阶段
文档切片后,需要对其建立索引,以便后续检索,常见方案用嵌入(Embedding)模型将切片向量化,并存储到数据库中。
将文本转为高维向量,用于表示文本语义,相似文本映射相近的向量上,检索根据问题的向量找到相似度高的文档切片
在实践中,单纯升级Embedding模型就可以显著提升检索质量,结合Ragas来测试
存储:最简单使用内存向量数据库,但是不能持久化,可以用开源的向量数据库,比如Milvus、Qdrant等。
检索召回阶段
主要问题就是: 很难从众多文档切片中,找出和用户问题最相关、且包含正确答案信息的片段
从切入时机来看,可以将解法分类两类
- 执行检索前:很多用户问题描述不完整,甚至有歧义,需要想办法还原用户的真实意图,以便提升检索效果。
- 执行检索后:可能会发现存在一些无关信息,减少无关信息切片,避免干扰下一步答案生成。
| 时机 | 改进策略 | 示例 |
|---|---|---|
| 检索前 | 问题改写 | 「附近有好吃的餐厅吗?」=> 「请推荐我附近的几家评价较高的餐厅」 |
| 问题扩写 通过增加更多信息,让检索结果更全面 | 「张伟是哪个部门的?」=> 「张伟是哪个部门的?他的联系方式、职责范围、工作目标是什么?」 | |
| 基于用户画像扩展上下文 结合用户信息、行为等数据扩写问题 | 内容工程师提问「工作注意事项」=> 「内容工程师有哪些工作注意事项」 项目经理提问「工作注意事项」=> 「项目经理有哪些工作注意事项」 | |
| 提取标签 提取标签,用于后续标签过滤+向量相似度检索 | 「内容工程师有哪些工作注意事项」=>
|
|
| 反问用户 | 「工作职责是什么」=> 大模型反问:「请问你想了解哪个岗位的工作职责」 实现反问的提示词可以参考:10分钟构建能主动提问的智能导购 | |
| 思考并规划多次检索 | 「张伟不在,可以找谁」 => 大模型思考规划: => task_1:张伟的职责是什么, task_2:${task_1_result}职责的人有谁 => 按顺序执行多次检索 | |
| ... | ... | |
| 检索后 | 重排序 ReRank + 过滤 多数向量数据库会考虑效率,牺牲一定精确度,召回的切片中可能有一些实际相关性不够高 | chunk1、chunk2...、chunk10 => chunk 2、chunk4、chunk5 |
| 滑动窗口检索 在检索到一个切片后,补充前后相邻的若干个切片。这样做的原因是:相邻切片之间往往存在语义联系,仅看单个切片可能会丢失重要信息。 滑动窗口检索确保了不会因为过度切分而丢失文本间的语义连接。 | 常见的实现是句子滑动窗口,你可以用下方的简化形式来理解: 假设原始文本为:ABCDEFG(每个字母代表一个句子) 当检索到切片:D 补充相邻切片后:BCDEF(前后各取2个切片) 这里的BC和EF是D的上下文。比如:
|
|
| ... | ... |
使用大模型扩写问题
将单一查询改为多步骤查询
提取标签增强检索:
在向量检索的基础上,添加标签过滤来提升检索精度,类似图书馆既有书名检索,又有分类编号系统,让检索更精准
标签提取关键:
1. 建立索引时,从文档切片中提取结构化标签
1. 检索时,从用户问题中提取对应的标签进行过滤
当我们建立索引时,可以将这些标签与文档切片一起存储。这样在检索时,比如用户问"张伟是哪个部门的",我们可以:
- 从问题中提取人名标签 {"key": "人名", "value": "张伟"}
- 先用标签过滤出所有包含"张伟"的文档切片
- 再用向量相似度检索找出最相关的内容
这种"标签过滤+向量检索"的组合方式,能大幅提升检索的准确性。特别是在处理结构化程度较高的企业文档时,这个方法效果更好。
重排序: 先从向量数据库中检索召回 20 条文档切片,再借助阿里云百炼提供的文本排序模型进行重排序,并且筛选出其中最相关的 3 条参考信息。
运行代码后你可以看到,同样是 3 条参考信息,这次大模型能够准确回答问题了。
生产答案阶段
可能遇到的问题:
- 没有检索到相关信息,捏造答案。
- 检索到了相关信息,但是大模型没有安装要求生产答案。
- 检索到了相关信息,也给除了答案,但希望ai给出更全面的答案。
1、选择合适的大模型
- 如果只是简单的信息查询总结,小参数量的模型足以满足需求,比如 qwen-turbo。
- 如果你希望答疑机器人能完成较为复杂的逻辑推理,建议选择参数量更大、推理能力更强的大模型,比如 qwen-plus甚至是 qwen-max。
- 如果你的问题需要查阅大量的文档片段,建议选择上下文长度更大的模型,比如 qwen-long、qwen-turbo或qwen-plus。
- 如果你构建的 RAG 应用面向一些非通用领域,如法律领域,建议使用面向特定领域训练的模型,如通义法睿。
2、充分优化提示词模板比如:
- 明确要求不编造答案:提示词比如‘如果所提供信息不足回答问题,请明确告“根据现有信息,我无法回答这个问题。” “切勿编造答案”’。
- 添加内容分隔标记,将提示词和检索切片明确分开,以便大模型正确理解你的意图。
- 根据问题类型跳出模板: 不同问题回答范式可能不同,借助大模型识别问题类型,然后映射不同的提示词模板; 比如有些问题希望大模型先输出整体框架,再输出细节;有些问题希望大模型言简意赅得出结论。
3、调整大模型参数比如:
- 希望输出相同问题下,输出内容尽可能相同,每次模型调用传入相同的seed值。
- 回答问题不要总是用重复的句子,适当调高presence_penalty值。
- 查询事实性内容,降低temperature或top_p的值;反之查询创造性内容,适当增加他们的值。
- 如果需要限制字数(如生成摘要、关键词)、控制成本或减少相应时间的场景, 可以适当调低max_tokens的值,但若过小,可能导致输出阶段,反之需要生成大段文本,可以调高 它的值。
- 你也可以查阅通义千问 API Reference,来了解更多参数的使用说明。